数据中心化和标准化
本文共 742 字,大约阅读时间需要 2 分钟。
简介:
意义:数据中心化和标准化在回归分析中是取消由于量纲不同、自身变异或者数值相差较大所引起的误差。 原理:数据标准化:是指数值减去均值,再除以标准差; 数据中心化:是指变量减去它的均值。 目的:通过中心化和标准化处理,得到均值为0,标准差为1的服从标准正态分布的数据。在回归问题和一些机器学习算法中,以及训练神经网络的过程中,还有PCA等通常需要对原始数据进行中心化(Zero-centered或者Mean-subtraction)处理和标准化(Standardization或Normalization)处理。
- 目的:通过中心化和标准化处理,得到均值为0,标准差为1的服从标准正态分布的数据(即下面x’的数据分布~N(0,1))。计算过程由下式表示:
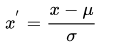 原因:在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表征的。很显然,这些特征的量纲和数值得量级都是不一样的,而通过标准化处理,可以使得不同的特征具有相同的尺度(Scale)。这样,在学习参数的时候,不同特征对参数的影响程度就一样了。简言之,当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理。
原因:在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表征的。很显然,这些特征的量纲和数值得量级都是不一样的,而通过标准化处理,可以使得不同的特征具有相同的尺度(Scale)。这样,在学习参数的时候,不同特征对参数的影响程度就一样了。简言之,当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理。
下图是二维的示例:
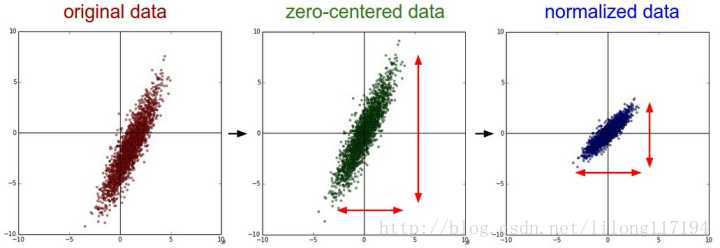
- 左图表示的是原始数据
- 中间的是中心化后的数据,可以看出就是一个平移的过程,平移后中心点是(0,0)。同时中心化后的数据对向量也容易描述,因为是以原点为基准的。(做了一次分布的空间转换)
- 右图将中心化后的数据除以标准差,得到为标准化的数据,可以看出每个维度上的尺度是一致的(红色线段的长度表示尺度),而没有处理之前的数据是不同的尺度标准。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。(做了一次分布的空间转换)
参考:
附:
你可能感兴趣的文章
聊聊性能:全链路压测 overview
查看>>
Java+Maven+selenium+testng+reportng自动化测试框架(简易搭建说明)
查看>>
WEB模糊查询注意的问题(排除%等通配符并支持不连续关键字查询)
查看>>
PostgreSQL中表的阶层数据取得方法
查看>>
如何用产品思维迭代项目管理流程?(创业有感)
查看>>
Linux ALSA 声卡驱动之一:ALSA架构简介
查看>>
Linux ALSA 声卡驱动之二:声卡的创建
查看>>
Linux ALSA 声卡驱动之三:PCM设备的创建
查看>>
Linux ALSA 声卡驱动之四:Control设备的创建
查看>>
Linux ALSA 声卡驱动之五:移动设备中的ALSA(ASoc)
查看>>
Linux ALSA 声卡驱动之六:ASoc架构中的Machine
查看>>
Linux ALSA 声卡驱动之七:ASoc中的Codec
查看>>
android电池系统
查看>>
android4.x 耳机插拔检测机制
查看>>
Android 4.x耳机插拔检测实现方法
查看>>
android修改开机动画和铃声
查看>>
android audio音量控制流程
查看>>
解密回声消除技术之一(理论篇)
查看>>
Speex编解码在Android上实现
查看>>
speex回音消除
查看>>